Text format allows reading and writing of text file formats based on sequential point data items. One point data is usually one text line, but it is also possible to handle data divided to several lines. Important thing is that each point data is structurally identical.
Text format header file can contain macros and file attributes. Because the line coding is based on the line numbers, letter X is added to the field T2 of the latter of adjacent lines with same number.
If common converter setting Convert arcs is on, arcs in the file are converted to three point arcs. Otherwise center points are written.
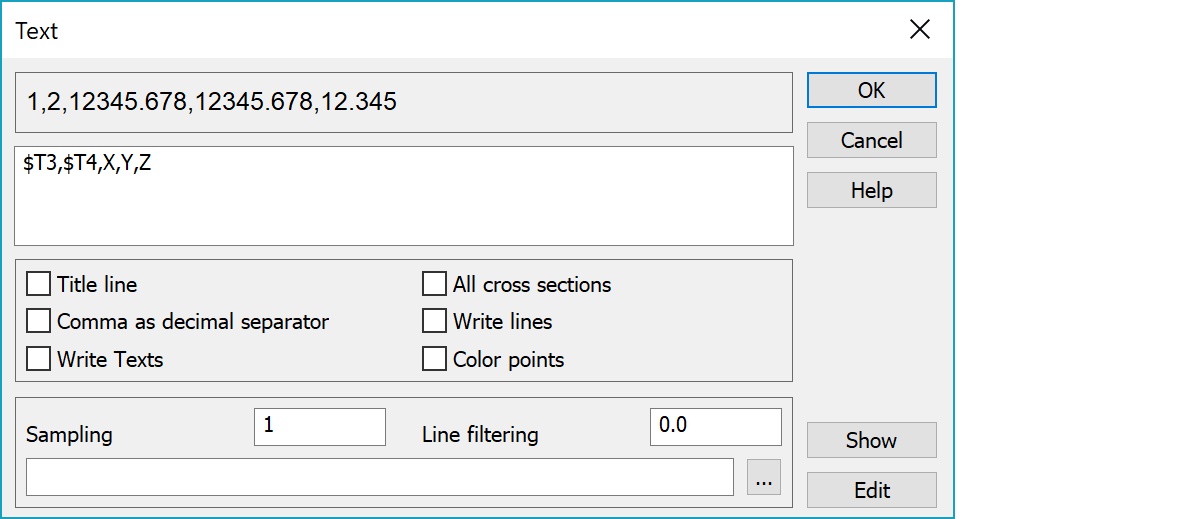
Definition is written to the big text field and example formatting is displayed above it. Field indexes are used as attribute example values and constant real values are displayed for coordinates X, Y and Z. Format definition can be divided to several lines, but possible spaces between field definitions must still exist at the end of the line.
Writes title row with field ids or skips first line in reading.
If the code file is given, code field descriptions are used for fields and program's own descriptions are used for known calculation attributes. Because code file attribute name descriptions are code specific, they cannot be used in common title row.
Uses comma as a decimal separator in writing. In reading, both comma and point are accepted as a desimal separator.
Writes also text points using same format as other points. The text itself can be found from the attribute TEXT.
Writes all cross sections. Default is to write only current cross section.
Reads and writes only lines. Coordinates X, Y and Z refer to the line or area reference point coordinates. Only line attributes are read or written. Line points can be read or written by using the square bracket syntax explained in the Lines section below.
Reads points as color points, which are drawn as colored squares. Color is transferred to the point draw data with the #COLOR macro and default size is calculated from the average point density. Size or its multiplier can also be given in SymbolSize-settings in field settings.
Simple test filtering, that reads points from the file with given interval. Affects last after classification and coordinate filtering.
Line filtering works with vector file containing breaklines and the fetch distance. The upper field contains the fetch distance and the lower field vector file, which should be in 3D binary format. Filtering checks all breaklines in the given file. If the line is closed area, points inside it are accepted. Otherwise points within given fetch distance from the line are accepted.
Opens example line in text editor with following format:
T3 T4 X Y Z
Koodi Tunnus X Y Z
1 2 12345.678 12345.678 12.345
123456789012345678901234567890123456789012345678901234567890
1 2 3 4 5 6
First title line uses attribute ids and second attribute names. Third line is actual format example. Two bottom lines display column index ruler.
Opens format definition in editable selection list. Each field is listed in its own line and can be edited with display format editing.
The Text format is based on sequential field definitions. Each one defines one data item (field, attribute or coordinate). Adjacent definitions are separated by space or other separator character. In most cases, same format definition works with both reading and writing. In practice this means, that written data values are separated somehow from each other.
For example, traditional Geonic-format:
9 0 234 3199 6697091.114 3444140.918 11.545
is handled by the following format definition:
$T1@8< $T2@8< $T3@8< $T4@8< $X%.3@14 $Y%.3@14 $Z%.3@14
Previous example defines format with four code fields (T1-T4), each clipped to eight character field and after that, coordinate values X, Y and Z in 14 character fields with three decimals.
Format can handle degrees, minutes and seconds. Degree values stored to point X- and Y-fields can be read and written using different formats and unit divisions. This works with the coordinate transformation allowing automatic handling of geographical latitude and longitude values. Additionally, Text format can read and write also sounding points, profiles and cross sections.
Single data item definition contains following parts:
$NAME@WIDTH=FILL%FORMAT.DEC $ NAME code/attribute/coordinate name (T1, MAT, X). % FORMAT degree/minute/second format definition. . DEC amount of decimals, default from converter settings. @ WIDTH field width, negative aligned to left. = FILL field fill character, space by default.
Attribute definition $ can be replaced with £ for line and profile points. It searches attribute also from parent line or profile, if is is not found from the point itself. In reading attribute marked with £ is set to parent line or profile. With single points definition £ works exactly like $.
Fill defintion (FILL) is considered to be additional definition for field width (WIDTH) and amount of decimals (DEC) is additional definition for number format (FORMAT). Additionally, there can be special characters at the end of the field definition for data clipping and field separation. Definition can also be either single or double quoted constant text.
Data name (NAME) can be code field name (T1-T6), any attribute name (MAT, DATE, TIME) or one of the following coordinate definitions:
X, Y, Z Point X, Y or Z-coordinate. A, B Bore or profile point section value (A) or side offset (B) D, G, T Point direction in degrees (D), gons (G) or default units (T)
If the write converter coordinate settings has any coordinate transformations, original coordinates are stored to the attributes _X, _Y and _Z. This way it is possible to use two different coordinate systems in the same line:
$T4@8< $_X%.3@14 $_Y%.3@14 $X%.3@14 $Y%.3@14
Additionally, special attribute name 0 is reserved for empty attribute. Writing it outputs just zero and reading it simply skips the value. For example, reading just coordinates from Geonic-format:
$0@8 $0@8 $0@8 $0@8 X%.3@14 Y%.3@14 Z%.3@14
Format definition (FORMAT) and decimal part (DEC) are given with common value formatting rules.
Examples:
X@14%.3 123456.789 Writing with three decimals X@14%+.3 +123456.789 Sign also for positive values X@14%.-2 123500 Rounding with negative decimals $MISSING%.0 0 Missing numeric value as zero $MISSING%_.0 Missing numeric value as empty X@14%ddmm.3 0103.456 Degree part and minutes with decimals (NMEA) X@14%d°m^'s^".3 1°3'5.678" Separators °, ' and " $VALUE%.1"m" 1.2m Unit after value $VALUE%.1"value=&" value=1.2 Title before value $VALUE%.1"'&'" '1.2' Value is single quotes $VALUE%.1'"&"' "1.2" Value in double quotes
Data width (WIDTH) defines the width of the written field and optional fill character (FILL) makes it possible to fill the field with some other character other than default space. Negative width aligns data left inside the field. Otherwise, default right alignment is used.
If the width definition is omitted, data is written by using simply its own width. If the data is wider than given field width, the whole data width is used by default. Special characters < and > at the end of definition can be used to clip data either from end (<) or from beginning (>).
Examples:
$T4@8 123 Align right, fill with spaces $T4@-8=0 12300000 Align left, fill with zeroes X@14=. ....123456.789 Align right, fill with points $PATH@14 c:/foo/bar/bat.txt Long data written wider than field $PATH@14> oo/bar/bat.txt Long data clipped from beginning $PATH@14< c:/foo/bar/bat Long data clipped from end $0%.1@8 0.0 Empty attribute with one decimal £LENGTH%.2@8 0.00 Line attribute with one decimal
For constant text handling data definition can also be text inside single or double quotes. In writing the text inside quotes is written directly and in reading same amount of characters is skipped. If the definition starts with double quotes, it can contain single quotes and vice versa.
If single or double quotes contain normal data definition starting with character $, data is written quoted and read from inside quotes. All normal data definition directives can be used also with quotes. When using quotation with wide field aligning, it must be noted that fill characters go outside of quotes.
Examples:
"foobar" foobar Constant text writing "'foobar'" 'foobar' Constant text containing single quotes '"foobar"' "foobar" Constant text containing double quotes "$T4" "123" Code field quoted with double quotes '$X@14' '697295.748' Coordinate quoted with single quotes
By default, separator character between data items can be space, tabulator, comma, semicolon, vertical bar or ampersand. Tabulator is given with tilde character (~) in definition. Empty separator ampersand works only as separator between definitions and is never written to the file. It allows writing data together without separator. If data definition contains width, space separator is not written to the file. Other separators ar written normally with width definitions also. Vertical bar works as a line feed, making it possible to write multiline formats.
Examples:
$T4@6 Z@10 1234 12.345 Constant width fields
$T4,Z 1234,12.345 Comma separated fields
$T4@6,Z@10 1234, 12.345 Constant width comma separated fields
$T4&Z 123412.345 Fields written together
$T4|Z 1234 First line of multiline format
12.345 Second line of multiline format
T1~T2~T3 12 34 56 Tabulator separated code fields
"KP"&T4 KP123 Constant text together with code field
Attributes containing dates or times can be read and written in different formats. The format is defined by characters Y, YY, YYYY (year), M, MM (month), D, DD (day), h, hh (hour), m, mm (minute), s, ss (second) and freely selectable separator characters between them. Year defined with two characters (YY) is written with two numbers (09). Other values defined with two character are filled with zeroes from left (01:03:05). Seconds can be displayed with decimals (.2). Written date must be stored to the attribute with format 12.7.2009 (D.M.YYYY) and time with format 12:34:56 (hh:mm:ss).
Examples:
$DATE%D.M.YYYY 12.7.2009 3D-Win attribute date format $TIME%hh:mm:ss 12:34:56 3D-Win attribute time format $DATE%YYYY-MM-DD 2009-07-12 ISO 8601 standard date format $TIME%hh:mm:ss.2 12:34:56.78 Seconds with two decimals $DATE%DDMMYY 120709 Year with two numbers
RGB color values can be read and written with characters R (red), G (green), B (blue) and A (transparency). Single letter means color component as a normal integer value and two letters means base 16 representation. Space separator can be given with underscore (_).
Examples:
$COLOR%RRGGBB FF0000 Red color id 3D-Win default format $COLOR%RRGGBBAA FF0000FF Red color with transparency $COLOR%R_G_B 255 0 0 Red color in separate components $COLOR%C 192 Greyscale value
Writing accepts same macros used in point group and attribute method. Normal #-definition writes only given macro value. Additional definition = can be used to prefix value with macro id and equality character. Macro #NAME writes T3-field code explanation from the code file. This requires code file name in the commom converter settings.
Reading accepts drawing data macros (#COLOR, #SIZE, etc.).
Examples:
#NAME Hajapiste Code explanation from the code file #=NAME NAME=Hajapiste Id and code explanation from the code file #SLOPE@8%.4 -0.1224 Line slope with four decimals #COUNT 12 Amount of points in line
Normal $-definition writes only given attribute value. Additional definition = can be used to prefix value with attribute id and equality character. Wildcard character * can be used write all remaining attributes. If no separator character is given after * definition, attributes are separated by the previous separator character.
When reading attributes with the = character, possible id is removed from the value. When reading all attributes with the definition $=*, attributes are read as long as they contain equality character. Attributes written with the definition *= cannot be read back with the same definition.
Definition $# can be used to get attribute real value from the code file when writing. For example, definition $#T3 gets code description and definition $#MAT gets material name. This requires code file name in the commom converter settings.
Examples:
$T1 9 Field T1 value $=T1 T1=9 Field T1 id and value $#T3 Hajapiste Code explanation from the code file $* 1 2 3 4 All attribute values $=* T1=1 T2=2 T3=3 T4=4 All attribute ids and values $T3,$=* 3,T1=1,T2=2,T4=4 Code and the rest of the attributes $T3,'$=*' 3,T1='1',T2='2',T4='4' Code and the rest quoted
Line points can be written with the repeated block definition in square brackets. The block contains single line point write definition using normal write rules. If no separator is given before the end of the square bracket block, the previous separator character is used as a separator between blocks. This copied separator character is not written after last block.
Examples:
$T2 [X.1 Y.1 Z.1] 2 12.3 67.7 1.2 98.7 54.3 3.4 Line number and coordinates $T1,$T2,$T3,[X.1,Y.1] 1,2,3,12.3,67.7,98.7,54.3 Surface, line, code and coordinates $T2 [$T4 X.1 Y.1] 2 1 12.3 67.7 2 98.7 54.3 Line, coordinates and point number $=* [X.1 Y.1] T1=1 T2=2 12.3 67.7 98.7 54.3 Attributes and coordinates $T2 $=* [X.1,Y.1 ] 2 T1=1 12.3,67.7 98.7,54.3 Attributes and coordinates
Lines starting with comment character (!) are skipped in reading. Comment lines are not allowed between data items in multiline formats.
Breaklines are interpreted based on content of code field T2. If the field is empty or zero, point is handled as a single point. Otherwise points are added sequentially to breakline and new line is started, when the line number (T2) or code (T3) changes.
There are some special settings related to this converter.
Four strings classifying text format special characters. By changing these it is possible to read formats containing characters normally used as control characters in text format definitions.
Escapes Removes special meaning of the next character, default "^\". Separators Allowed defintition separator characters, default " ~,;|&". Quotes Quotation characters in definitions, default " and '. Comment Comment characters at the beginning of the line, default ! and #.
Note that Escapes and Quotes settings affect only in format definitions. The data itself can contain these characters freely. Separator characters affect in both definition and actual data. Comment characters have meaning only in data.
Lukuasetus Topcon-formaatia varten.
31 To read Topcon-data. Converts $-characters to spaces and reads linenumber after &-character.
102$7006019.356$22484348.667$23.197$710$Type=400$Asennusvuosi=1998 103$7006019.213$22484348.557$23.182$715$Halkaisija=160$Type=P V C$Asennusvuosi=1995&1@
See also: Common special settings